多级降采样
应用场景
在DevOps或Iot等场景中,存在这样一种需求,我们对历史数据明细不再关注,转而关注数据特征,比如最大值,最小值,平均值等。
传统的解决方案是存储所有明细数据,需要时查询数据并计算,亦或者通过Continue Query 后台任务,提前计算好,把结果数据存入一个新表,加速计算效率。但是,如果业务保留历史数据的目的只是为了做一些数据特征计算,上面的解决办法因为保留明细数据,时间越长,存储成本越高。
多级降采样
多级降采样与普通降采样的区别在于,多级降采样可以对不同时间段的数据执行不同的降采样策略,比如我希望过去1周到1月内的数据,按时间线每15分钟聚合一次(忽略具体聚合方式),过了1月的历史数据按时间线每1小时聚合一次。
实际业务中用户对不同时间段的降采样要求是不一样的,用户可能对近期的数据比较敏感而对长远的数据需求较少,所以需要根据实际业务对数据进行不同的多级降采样策略。采用多级降采样的方式既满足了用户对高价值数据的查询需求,又兼顾了存储效率。
场景举例
多重降采样场景举例:7天内原始数据直接入库,7-30天数据,15min粒度降采样后入库,30天-12个月的数据,1h粒度降采样后入库。 如下图所示,假设今天是2022-12-31,蓝色部分是7天内的数据,黄色部分是7-30天数据,橙色部分是30天-12个月的数据。每过一段时间,数据库会把蓝色部分的数据以15min为粒度聚合放到黄色区域中;每过一段时间,数据库会把黄色部分以1h为粒度聚合放到橙色区域中,注意这里1h是15min的倍数,所以可以方便地聚合。 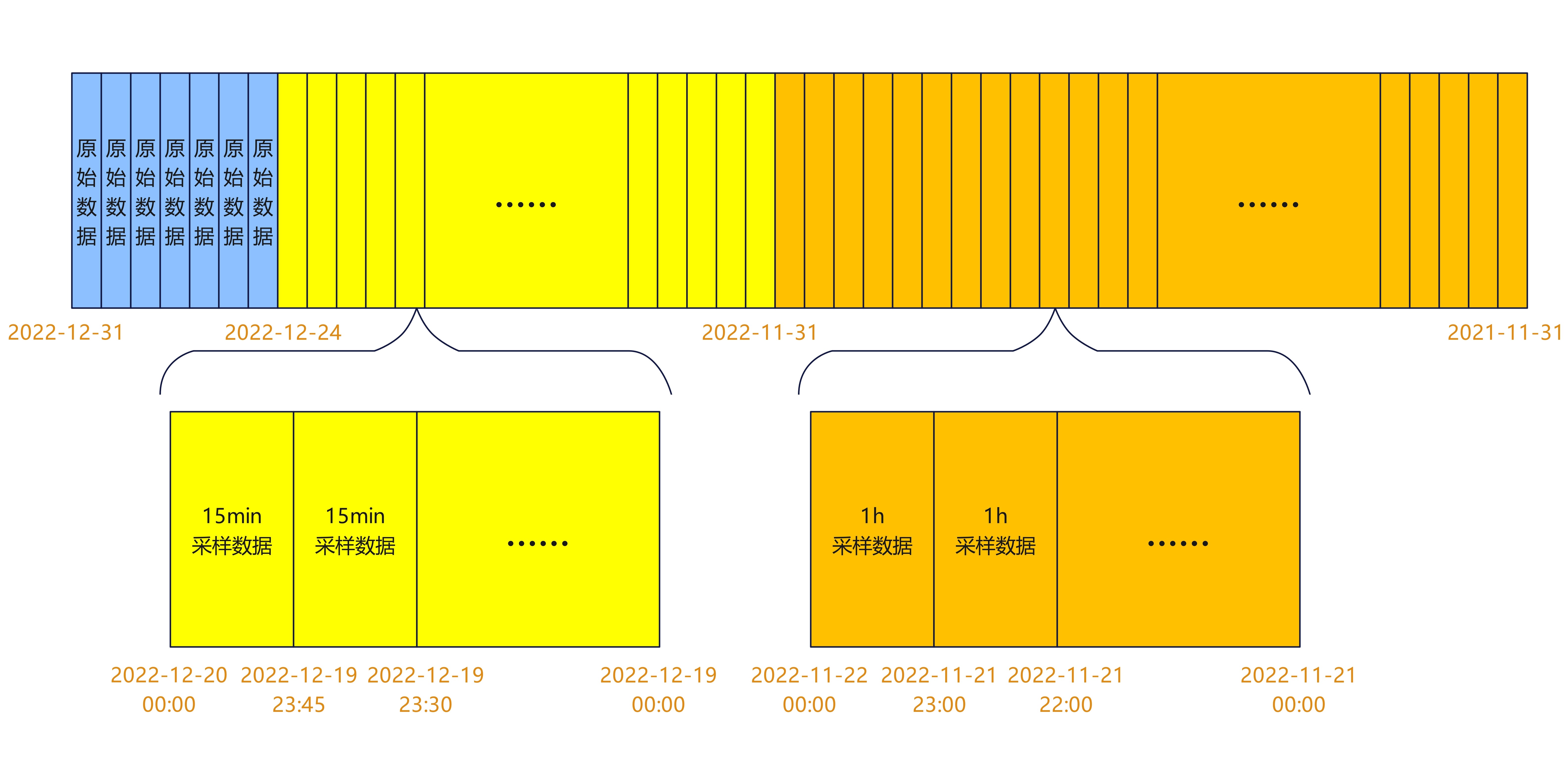
创建降采样
语法:
Create DownSample [on <rp_name>| on <dbname>.<rp_name>| ]((dataType(aggregators)...)) With Duration <timeDuration> SampleInterval(time Durations) TimeInterval(time Durations)
参数说明:
| Duration | SampleInterval | TimeInterval |
|---|---|---|
| 降采样后数据的保留时间 | 执行下一级降采样时间 | 采样Interval |
聚合方法定义格式:
dataType(aggfunctions...)
聚合方法举例:
integer(first,sum,count,last,min,max)
integer(min,max),float(sum)
限制说明:
- SampleInterval, TimeInterval 指定的采样策略数量必须相同,比如其中有一项的数量是3,其他项的数量也必须是3;
- SampleInterval, TimeInterval 为一一对应关系、每个数组内为倍数关系;
举例说明:
首先,创建一个保留策略rp1,数据保留时长为7天,每天1个shard
> create retention policy rp1 on mydb duration 7d replication 1 shard duration 1d
其次,假设需要在刚新增的rp1之上创建一个降采样任务,采样后的数据的保留时长设为7天,过去1天内的数据保持数据明细,过去1天-2天内的数据按1分钟粒度对数据进行采样,2天以后的数据,按3分钟的粒度对数据进行降采样。
> Create DownSample on rp1
(float(sum,last),integer(max,min))
With Duration 7d
sampleinterval(1d,2d)
timeinterval(1m,3m)
需要⚠️注意的是:
这里的Duration控制降采样后的数据的保留时长,会同步更新rp1的Duration。可以设置为和rp的duration相同值。仅支持first,last,sum,max,min,mean,count 7种。float(sum,last)代表表内所有float类型的字段都使用sum()和last()聚合函数对数据进行降采样,integer(max,min)同理。
约束条件:
sampleinterval(1d,2d),后一个时间是前一个时间的整数倍关系。这种写法是不正确的: sampleinterval(2d,3d) ❌
同样,timeinterval(1m,3m) ✅,timeinterval(5m,6m) ❌
sampleinterval 和 timeinterval括号内的值的数量也要一一对应。
sampleinterval(1d,2d) timeinterval(1m,3m) ✅
sampleinterval(1d,2d) timeinterval(3m) ❌
sampleinterval(1d) timeinterval(1m,3m) ❌
案例
环境准备,以openGemini单机程序为例。
修改配置文件
openGemini.singlenode.conf,开启多级降采样功能# 如果有这两个配置项,请删除或注释,v1.3.1版本后将从单机配置文件中删除 [meta] ... # num-of-shards = 2 # ptnum-pernode = 3 #在任何位置新增如下配置,开启多集降采样(downsample)功能 [downsample] enable = true check-interval = "30m"启动ts-server
> ts-server --config openGemini.singlenode.conf出现如下日志,表示该功能已开启
/tmp/openGemini/logs/single.log:35:{"level":"info","time":"2025-01-20T11:29:43.365047+08:00","msg":"Starting downSample enforcement service","hostname":"127.0.0.1:8400","check_interval":60,"location":"services/base.go:48","repeated":2}写入数据(Go语言代码)
package main import ( "context" "fmt" "math/rand" "sync" "time" openGemini "github.com/openGemini/opengemini-client-go/opengemini" ) func main() { //创建客户端 config := &openGemini.Config{ Addresses: []*openGemini.Address{ { Host: "127.0.0.1", Port: 8086, }, }, } client, err := openGemini.NewClient(config) if err != nil { fmt.Println(err) } //创建数据库,并关联数据保留策略 exampleDatabase := "ExampleDatabase" rpConfig := &openGemini.RpConfig{ Name: "rp1", Duration: "24h", ShardGroupDuration: "1h", IndexDuration: "1h", } err = client.CreateDatabaseWithRp(exampleDatabase, *rpConfig) if err != nil { fmt.Println(err) return } var wg sync.WaitGroup //开3个线程来写数据 //写入单条数据 for i := 0; i < 3; i++ { wg.Add(1) go func(i int) { exampleMeasurement := "ExampleMeasurement" for { point := &openGemini.Point{} point.SetMeasurement(exampleMeasurement) host := fmt.Sprintf("127.0.0.%d", i) point.AddTag("host", host) point.AddField("cpu", rand.Float64()) point.AddField("memory", rand.Intn(1000)) err = client.WritePoint(context.Background(), exampleDatabase, point, func(err error) { if err != nil { fmt.Printf("write point failed for %s", err) } }) fmt.Printf("at %d \n", i) if err != nil { fmt.Println(err) break } time.Sleep(1 * time.Second) } }(i) } wg.Wait() }这个Demo程序主要完成了如下一些工作:
a. 创建数据库ExampleDatabase , 并关联数据保留策略 rp1(数据保留时间为24小时,每1小时产生一个分片)
> show databases name: databases +-----------------+ | name | +-----------------+ | ExampleDatabase | +-----------------+ 1 columns, 1 rows in set > show retention policies +------+----------+--------------------+...+----------------+----------+---------+ | name | duration | shardGroupDuration |...| index duration | replicaN | default | +------+----------+--------------------+--------------+---------------+----------+ | rp1 | 24h0m0s | 1h0m0s |...| 1h0m0s | 1 | true | +------+----------+--------------------+--------------+---------------+----------+ 8 columns, 1 rows in setb. 开启三个线程,线程每1s写一条数据,每个线程对应一条时间线。
c. 数据样例
> select * from ExampleMeasurement name: ExampleMeasurement +-----------------------------+-----------------------+-----------+--------+ | time | cpu | host | memory | +-----------------------------+-----------------------+-----------+--------+ | 2025-01-20T05:02:28.32041Z | 0.19901648190029175 | 127.0.0.2 | 739 | | 2025-01-20T05:02:28.321154Z | 0.523898396259869 | 127.0.0.1 | 825 | | 2025-01-20T05:02:28.323599Z | 0.2952592203953564 | 127.0.0.0 | 562 | | 2025-01-20T05:02:29.88714Z | 0.6992184299086072 | 127.0.0.1 | 90 | | 2025-01-20T05:02:29.88736Z | 0.9440233357447462 | 127.0.0.2 | 622 | | 2025-01-20T05:02:29.887778Z | 0.40731955440979595 | 127.0.0.0 | 590 | | 2025-01-20T05:02:30.889635Z | 0.17295205384851764 | 127.0.0.0 | 640 | | 2025-01-20T05:02:30.889919Z | 0.8867266042676683 | 127.0.0.1 | 322 | | 2025-01-20T05:02:30.890166Z | 0.7617434331720145 | 127.0.0.2 | 413 | | 2025-01-20T05:02:31.910263Z | 0.9930840757764426 | 127.0.0.0 | 888 | | 2025-01-20T05:02:31.910264Z | 0.40816020746541026 | 127.0.0.2 | 756 | | 2025-01-20T05:02:31.910834Z | 0.03217675458413572 | 127.0.0.1 | 743 | | 2025-01-20T05:02:32.914047Z | 0.9981393254182734 | 127.0.0.1 | 292 | | 2025-01-20T05:02:32.914058Z | 0.9652793958030145 | 127.0.0.2 | 52 |创建降采样任务
> show shards name: ExampleDatabase +----+-----------------+------------------+...+----------------------+----------------------+.. | id | database | retention_policy |...| start_time | end_time |.. +----+-----------------+------------------+...+----------------------+----------------------+.. | 1 | ExampleDatabase | rp1 |...| 2025-01-20T03:00:00Z | 2025-01-20T04:00:00Z |.. +----+-----------------+------------------+...+----------------------+----------------------+.. 10 columns, 1 rows in set > show retention policies +------+----------+--------------------+...+----------------+----------+---------+ | name | duration | shardGroupDuration |...| index duration | replicaN | default | +------+----------+--------------------+--------------+---------------+----------+ | rp1 | 24h0m0s | 1h0m0s |...| 1h0m0s | 1 | true | +------+----------+--------------------+--------------+---------------+----------+ 8 columns, 1 rows in set # 创建成功无提示 > create downsample on rp1 (float(max),integer(min)) with duration 24h sampleinterval(1h,2h) timeinterval(1m,5m) >提示
- 降采样任务是RP粒度,RP下面的所有表的数据都会被处理。这里建议大家提前做好规划,不想被处理的数据,写入其他RP下,或者其他DB下。
- 降采样任务是按时间线对数据进行分组聚合
- 降采样任务是按数据类型来指定聚合方法,不关注具体某个字段(field)
- 创建降采样语句中的Duration最好与保留策略rp1的duration保持一致,否则会被覆盖。比如 rp1中是24h,如果创建降采样语句中设置为48h,那么rp1的Duration会随之变为48h,shardGroupDuration不变。
- 创建降采样语句中的sampleInterval必须要大于等于shardGroupDuration值,这里rp1的shardGroupDuration为1h。因为正在活动状态下的shard不能做降采样,降采样只针对历史shard。也存在例外,如果某历史shard频繁被查询,那么这个shard的数据也不会被降采样任务处理。
出现这条日志,表示降采样任务正在处理数据
{"level":"info","time":"2025-01-20T13:03:12.090108+08:00","caller":"downsample/service.go:71","msg":"start run downsample task with shardID:1,downsample level:1","hostname":"127.0.0.1:8400","trace_id":"0uCXLAg0000","op_name":"downSample_check"}降采样后的数据如何查询
降采样后的数据目录结构
> tree /tmp/openGemini/data/data/ExampleDatabase /tmp/openGemini/data/data/ExampleDatabase └── 0 └── rp1 ├── 1_1737342000000000000_1737345600000000000_1 │ ├── downsample_log │ └── tssp │ └── ExampleMeasurement_0000 │ └── 00000003-0000-00000002.tssp ├── 2_1737345600000000000_1737349200000000000_2 │ ├── downsample_log │ └── tssp │ └── ExampleMeasurement_0000 │ ├── 00000005-0000-00000002.tssp │ └── 00000006-0000-00000002.tssp ├── 3_1737349200000000000_1737352800000000000_3 │ ├── compact_log │ ├── downsample_log │ └── tssp │ └── ExampleMeasurement_0000 │ └── 00000003-0001-00000001.tssp ├── 4_1737352800000000000_1737356400000000000_4 │ └── tssp │ └── ExampleMeasurement_0000 │ └── 00000001-0000-00000000.tssp降采样后的数据,只能通过指定的那几种聚合方法才能访问
> show field keys name: ExampleMeasurement +----------+-----------+ | fieldKey | fieldType | +----------+-----------+ | cpu | float | | memory | integer | +----------+-----------+ 2 columns, 2 rows in set > show downsamples +--------+-------------------------+----------+----------------+--------------+ | rpName | field_operator | duration | sampleInterval | timeInterval | +--------+-------------------------+----------+----------------+--------------+ | rp1 | float{max},integer{min} | 24h0m0s | 1h0m0s,2h0m0s | 1m0s,5m0s | +--------+-------------------------+----------+----------------+--------------+ 5 columns, 1 rows in set > select min(memory) from ExampleMeasurement where time > '2025-01-20T03:00:00Z' and time < '2025-01-20T04:00:00Z' group by host name: ExampleMeasurement tags: host=127.0.0.0 +----------------------+-----+ | time | min | +----------------------+-----+ | 2025-01-20T03:38:00Z | 0 | +----------------------+-----+ 2 columns, 1 rows in set name: ExampleMeasurement tags: host=127.0.0.1 +----------------------+-----+ | time | min | +----------------------+-----+ | 2025-01-20T03:37:00Z | 0 | +----------------------+-----+ 2 columns, 1 rows in set name: ExampleMeasurement tags: host=127.0.0.2 +----------------------+-----+ | time | min | +----------------------+-----+ | 2025-01-20T03:33:00Z | 0 | +----------------------+-----+ 2 columns, 1 rows in set > select max(cpu) from ExampleMeasurement where time >= '2025-01-20T03:30:00Z' and time < '2025-01-20T04:00:00Z' group by host,time(10m) name: ExampleMeasurement tags: host=127.0.0.0 +----------------------+--------------------+ | time | max | +----------------------+--------------------+ | 2025-01-20T03:30:00Z | 0.9984655479770166 | | 2025-01-20T03:40:00Z | 0.9992629546337147 | | 2025-01-20T03:50:00Z | 0.9995725065691786 | +----------------------+--------------------+ 2 columns, 3 rows in set name: ExampleMeasurement tags: host=127.0.0.1 +----------------------+--------------------+ | time | max | +----------------------+--------------------+ | 2025-01-20T03:30:00Z | 0.9985828464178326 | | 2025-01-20T03:40:00Z | 0.9980818639725604 | | 2025-01-20T03:50:00Z | 0.9516030371044307 | +----------------------+--------------------+ 2 columns, 3 rows in set name: ExampleMeasurement tags: host=127.0.0.2 +----------------------+--------------------+ | time | max | +----------------------+--------------------+ | 2025-01-20T03:30:00Z | 0.9946351703332725 | | 2025-01-20T03:40:00Z | 0.9998730416901079 | | 2025-01-20T03:50:00Z | 0.9942326839779181 | +----------------------+--------------------+ 2 columns, 3 rows in set
显示降采样
语法: show 默认database 所有 downsample tasks:
SHOW DOWNSAMPLES
show 指定database 所有 downsample tasks:
SHOW DOWNSAMPLES ON <dtabase name>
举例说明:
> show downsamples on ExampleDatabase
+--------+-------------------------+----------+----------------+--------------+
| rpName | field_operator | duration | sampleInterval | timeInterval |
+--------+-------------------------+----------+----------------+--------------+
| rp1 | float{max},integer{min} | 24h0m0s | 1h0m0s,2h0m0s | 1m0s,5m0s |
+--------+-------------------------+----------+----------------+--------------+
删除降采样
语法: 删除数据库的所有降采样:
Drop DownSamples
Drop DownSamples on db0
删除指定RP的降采样:
Drop DownSample on rp1
Drop DownSample on db0.rp1