Release notes(v1.4.0)
大约 2 分钟约 697 字
openGemini v1.4.0版本是一个多副本性能优化版本
测试集群规格和拓扑
机器规格
华为云ECS 8vcpu 16GB c7n,2xlarge.2, SSD 40GB 共4台,1台用作执行机,3台用于部署集群。
数据规模
10万设备(时间线),846000000(8亿4千6百万行数据),一行数据包含10个指标数据,gzip压缩后30GB。
集群配置
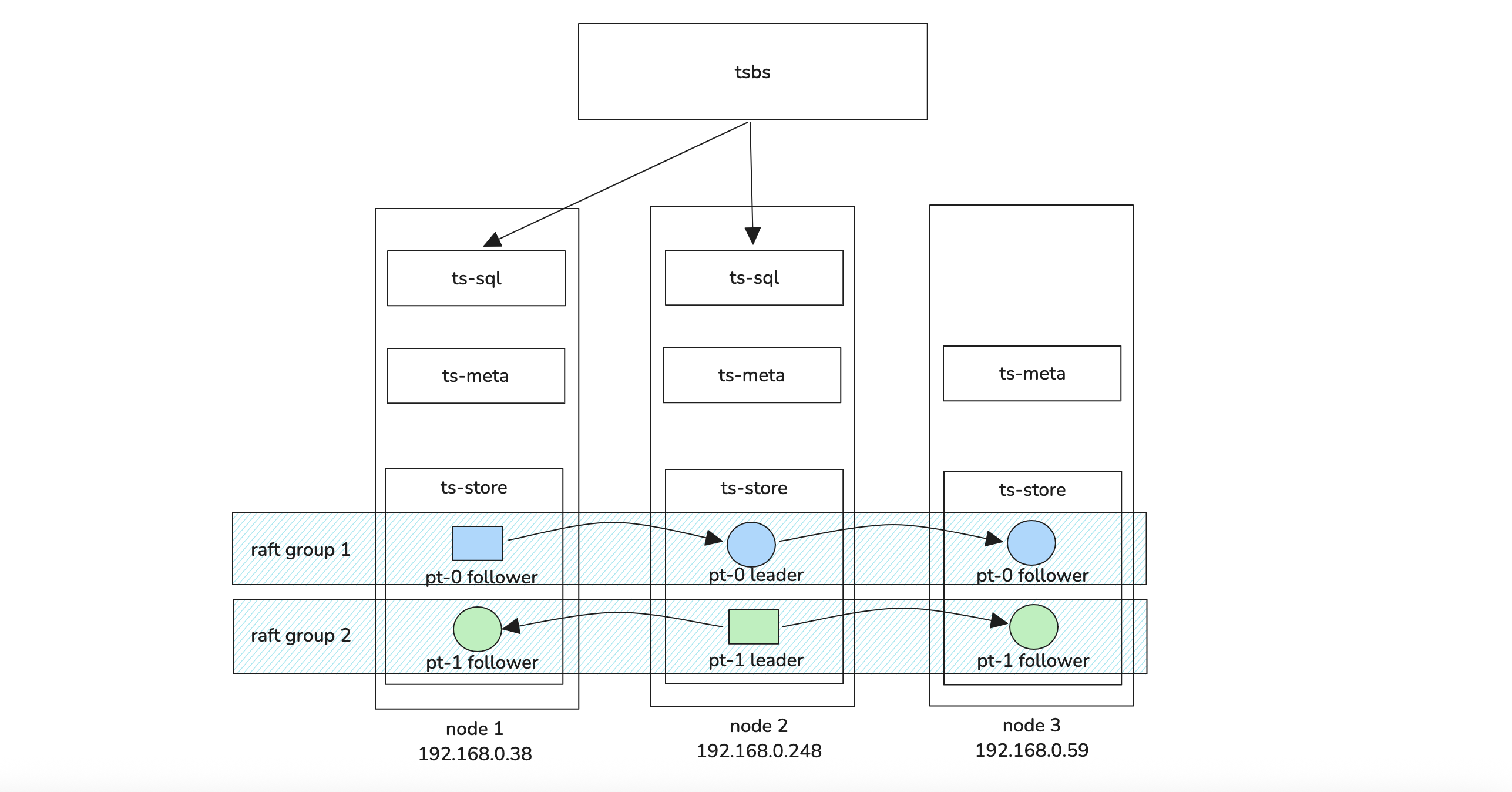
数据3副本,每节点2PT,其余默认,集群拓扑见上图。
写入性能
提示
如下性能数据仅做参考,不可直接用于任何商业决策
8并发往2个ts-sql批量写,batchsize为1000,写性能 722819.92 rows/sec(平均 72万rows/s)
- 资源消耗情况:
- Node-1: cpu 84%, mem 7.5%
- Node-2: cpu 68%, mem 7%
- Node-3: cpu 30%, mem 6.5%
- 资源消耗情况:
8并发往1个ts-sql批量写,batchsize为1000,写性能 521019.91 rows/sec(平均 52万rows/s)
- 资源消耗
- Node-1: cpu 92%, mem 7.5%
- Node-2: cpu 26%, mem 6.6%
- Node-3: cpu 24%, mem 6.7%
- 资源消耗
当只有1个sql时,所有数据处理都在node-1上,因此CPU利用率比较高。如果有2个ts-sql时,由于负载均衡并非完全均衡,因此node-1的负载相对高一些,总体性能提升了 40%
查询性能
| 查询场景 | 并发数 | 查询平均时延(单位ms) |
|---|---|---|
| single-groupby-1-1-1 | 4 | 1.98 |
| single-groupby-1-1-12 | 4 | 11.94 |
| single-groupby-1-8-1 | 4 | 5.23 |
| single-groupby-5-1-1 | 4 | 2.07 |
| single-groupby-5-1-12 | 4 | 5.17 |
| single-groupby-5-1-8 | 4 | 3.93 |
| cpu-max-all-1 | 4 | 2.64 |
| cpu-max-all-8 | 4 | 5.07 |
| double-groupby-1 | 4 | 4630.04 |
| double-groupby-5 | 4 | 10141.8 |
| double-groupby-all | 4 | 17060.1 |
| high-cpu-all | 1 | 35,201.1 |
| high-cpu-1 | 4 | 6.19 |
| lastpoint | 4 | 89.24 |
| groupby-orderby-limit | 1 | 9,225.74 |
由于内存只有16GB,因此并发数调整为4,high-cpu-all 和 groupby-orderby-limit这两个场景要消耗大量计算资源,因此并发数设置为1。从测试数据来看,openGemini查询性能依然具有竞争力领先优势。
资源消耗情况:
- Node-1: high-cpu-all和groupby-oderby-limit场景最高超过85%,其他场景保持在 mem 30%左右,部分简单场景更低。
- Node-2: high-cpu-all和groupby-oderby-limit场景最高超过85%,其他场景保持在 mem 30%左右,部分简单场景更低。
- Node-3: high-cpu-all和groupby-oderby-limit场景最高超过85%,其他场景保持在 mem 30%左右,部分简单场景更低。
问题修复
- 修复了2个备份恢复问题,其中包括Panic问题
- 修复查询结果数据的时间格式默认为rfc3339
- 修复子查询支持distinct
安全问题
CVE-2024-45337
升级依赖 golang.org/x/net from v0.26.0 to v0.33.0
CVE-2025-30204
升级依赖 github.com/golang-jwt/jwt/v5 from v5.0.0 to v5.2.2